从源码入手理解OLLVM(一)
OLLVM(全称 Obfuscator-LLVM)是基于 LLVM 源码二次开发的开源混淆编译器框架,它通过向 LLVM 编译流程中注入自定义混淆 Pass,实现控制流平坦化、虚假控制流等多种代码混淆功能,属于 LLVM 的第三方衍生版本,要了解OLLVM,先要了解LLVM。
clang编译器
Clang 是基于 LLVM编译器基础设施 实现的主流前端编译器。说到编译器,大家最熟悉的就是GCC,那Clang(编译器)和GCC有哪些不一样呢?支持多种语言:Swift/Rust/Objective-C,性能优化更好,模块化设计(前、中、后端解耦)。最重要的是LLVM 的中端优化基于 SSA 形式的 LLVM IR,这一点与 GCC 的 GIMPLE SSA 在思想上是相通的。但 LLVM IR 作为稳定、对外暴露的中间表示,使得定制 Pass(如 OLLVM)在工程实现上更为友好,这会使得该编译器在常量传播、死代码消除更精准,OLLVM作为二次开发的产物,也继承这一特点。如果你有过静态分析控制流平坦化函数中某个变量的经历,很容易就能观察到,某个变量从定义到后续使用的过程中,会有大量的其余变量来接收、转移,给人一种狡兔三窟的感觉,但这并不是混淆本身,只是编译器的优化策略使然。
SSA
静态单赋值,顾名思义,就是该变量从定义开始,只能被赋值一次。举个例子:
非SSA形式:
1 | int a = 1; // 第一次赋值 |
SSA形式
1 | int a1 = 1; // 初始赋值(版本1) |
这样操作有个好处,就是通过静态分析就能观察到变量的变化和赋值情况,观察到a5变量就意味着前面已经被赋值了4次。
AST(抽象语法树)
LLVM编译器中clang会将源码解析出树状结构
eg:
代码:
1 | while b ≠ 0: |
树形: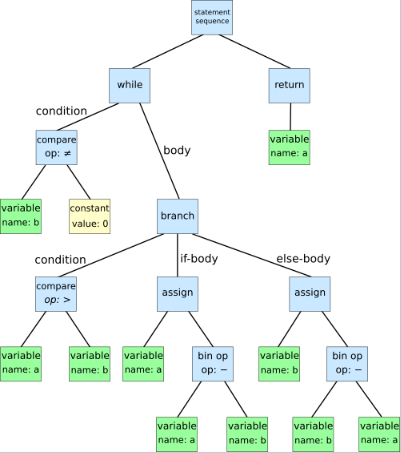
1 | ```plaintext |
Basic Block(基本块)
基本块是编译器根据AST转化出IR的同时,根据一些规则,同时划分出基本块:**唯一入口、遇到跳转或者返回(ret)会形成新的块,ida中cfg的代码块的划分也是基于这个规则。
IR(中间表达)
IR是编译过程中沟通源码与汇编的一种中间抽象语言表达,不仅仅是语法表示还有基本块这个骨架。有以下作用:
- 解耦 “前端(源码)” 和 “后端(机器码)”,实现跨语言、跨架构编译。
- 作为 “编译优化的统一载体”,实现高效、通用的代码优化。eg:
a1=1 → a2=a1+2会被优化为a2=3 - 降低编译器扩展 / 定制的复杂度。ollvm就是在这个阶段加入的混淆
GCC、LLVM都具有中间表达这种概念,但是LLVM是暴露开放的,有单独的中间文件,GCC相反。
IR中间表达继承了前端源码的语义,以类汇编的语法进行表达,才沟通起了整个编译过程的始末。
微码(mc),ida反编译过程中的一种中间表达,后面D810反混淆原理要进一步了解。