从源码入手理解OLLVM(三)
D810是很好的OLLVM反混淆插件,关于D810是如何工作的,这里有两篇很好的文档,D810: A journey into control flow unflattening、D810: Creating an extensible deobfuscation plugin for IDA Pro
从D810的插件源码里可以看到,D810实现了两个优化器,一个是指令优化器,一个是代码块优化器,指令优化主要目的是针对前面的OLLVM-指令替换混淆,但是,事实上ida的微码本身就有一定的反混淆和指令优化的功能,下面这个是ida终端的显示:
作为针对OLLVM反混淆的插件,D810的指令优化器的作用已经大幅下降,我们可以从一个时间线上窥见一二,2017年左右OLLVM官方版本就开始停止更新,同年,IDA对微码进行重大升级,显著增强了对混淆代码的分析能力。
D810 使用 IDA Pro 的 optblock_t 接口实现基本块优化,主要处理控制流平坦化。
反控制流平坦化流程
1. 调度器检测
1 | # 在optimize方法中检测调度器 |
2. 反平坦化核心
1 | def remove_flattening(self) -> int: |
3. 模拟执行确定目标
1 | def resolve_dispatcher_father(self, dispatcher_father, dispatcher_info): |
IDA微码()
IDA 微码是 Hex-Rays 反编译器使用的中间表示 (IR) 语言,位于汇编与伪代码之间,是 IDA 反编译流程的核心枢纽。它将不同架构的机器指令统一抽象,提供了更高级别、更易优化的代码表示形式。
微码通过多个“成熟度阶段”进行优化,每个阶段都有各自的优化重点。在IDA9.2之前可以通过lucid插件查看整个优化过程,9.2就有官方的查看器了。
| 成熟度名称 | 核心操作(优化方向) | 用途 |
|---|---|---|
| MMAT_GENERATED | 从汇编指令直接翻译为微码,无优化 | 作为后续所有优化的 “原始基础”,保留汇编的所有操作细节(如栈 / 寄存器操作) |
| MMAT_LOCOPT | 单个基本块内的局部优化:常量折叠、冗余指令消除、表达式化简(如 a+0→a)、死代码删除 | 精简单个块内的代码,提升微码简洁度,是反混淆中 “指令级化简” 的核心阶段 |
| MMAT_CALLS | 专门处理函数调用逻辑:解析传参方式(栈 / 寄存器)、统一返回值处理、内联简单函数 | 让函数调用更贴近高级语言表现,为后续全局优化梳理调用关系 |
| MMAT_GLOBPT1/2/3 | 全局优化的 3 个递进轮次:跨基本块的常量传播、全局死代码消除、控制流简化(合并冗余分支)、识别循环结构 | 从 “整个函数” 的维度精简逻辑,初步识别 / 消除跨块的混淆结构(如不透明谓词) |
| MMAT_LVARS | 局部变量分配:将寄存器 / 临时值映射为高级语言变量、推断变量类型与作用域 | 微码优化的最后阶段,为生成 C 风格伪代码(CTree)做准备,让结果更贴近原始源码 |
D810使用
IDA中快捷键“Ctrl+Shift+D”打开D810

点击上面的Edit:
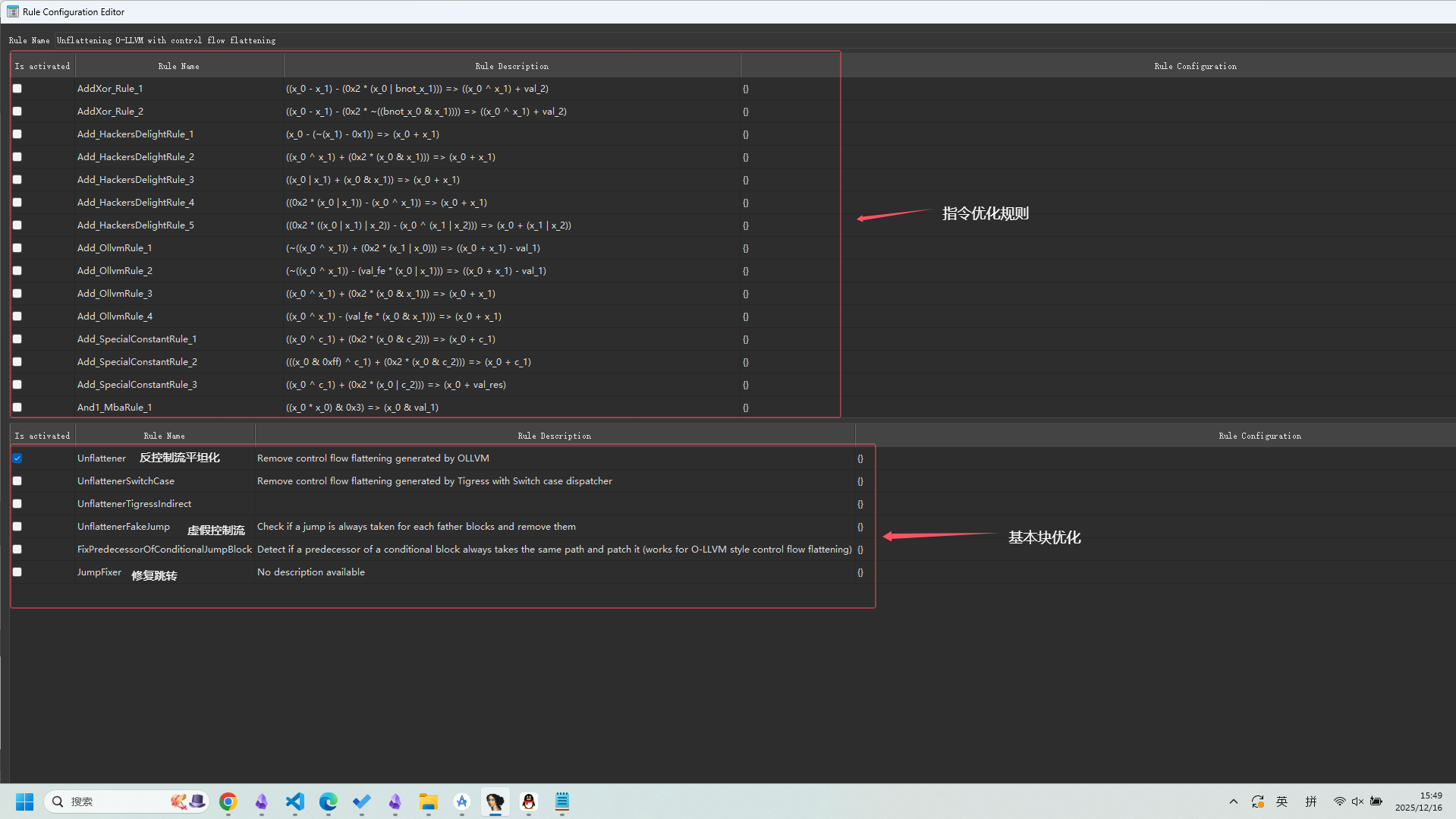
根据需要选择,也可以全选上,D810会自动匹配。指令优化器可以添加新规则。
点击Start后,在目标函数使用F5后D810就能正常工作了,可以处理控制流平坦化+虚假控制流,但是D810没办法处理魔改过的Flating。